UapiPro的限流器系统算是在立项早期就有了,初版就引入了自适应的限流器和算法。算是一个让我花了挺多心思的模块。
今天想聊聊我是怎么一步步把 UapiPro 这个限流器做出来的。
UapiPro
免费 Api 项目,拥有 77 个接口,550万+ 调用量
为什么不用go常见的令牌桶限流器?
限流本身就是为了公平,还有防止服务被打垮。常规的做法通常是基于令牌或用户身份做一个简单的令牌桶,比如用 golang.org/x/time/rate。
但 UapiPro 面对的场景更复杂一些。
除了常规的 API Token 限流,还有大量来自不同 IP 的匿名访问(免费公共用户)
一个固定的全局速率限制显然不够优雅。
举个例子,如果流量高峰期来了,服务已经快撑不住了,限流器还傻傻地按固定阈值放请求进来,那不就直接把服务器干死了?
反之,如果服务器明明很空闲,却因为一个固定的保守的阈值拒绝了正常用户,那体验也太差了
所以在我设想里面,这个限流器它应该在系统健康时尽可能多地处理请求,在系统过载时能迅速收紧、缓解,甚至能干掉那些坏家伙。
于是,这个多层次、自适应的限流系统诞生了
限流器的架构
整个限流系统一共有三层,从内到外。
- 令牌限流层
- 全局自适应层
- 主动防御层 (针对一些捣乱的IP打击与熔断)
下面我们一层一层来看。
1)高性能的令牌限流
先说说为什么要单独搞这一层。
UapiPro 的流量其实分两种:
- 一种是拿着 API Key 来的认证用户(我就简称VIP吧)
- 一种是直接访问公开接口的匿名用户
刚开始我想过用一个全局限流器搞定所有人,简单直接。
但问题来了:全局限流没法区分 VIP 和匿名用户。
- VIP 用户说:我买了 2000 req/s 的配额,但匿名用户把全局池子占满了,我根本用不上
- ok。那我把全局上限调高到 20000 QPS?这样VIP肯定够用了
- 结果匿名用户也能享受 20000 QPS,直接把服务打爆了
那有什么办法可以在给 VIP 高配额的同时,限制匿名用户呢...那把认证用户单独拎出来,给每个 Token 独立的限流策略。
这样 VIP 用户的配额是他自己的,普通用户的配额是他自己的,双方谁也不影响谁
那具体怎么弄呢?最常见的就是为每个 Token 创建一个 rate.Limiter 对象,放在一个 map 里:
limiters := make(map[string]*rate.Limiter)
但这有个非常大的问题,假如系统里有 10 万个 Token,就得常驻 10 万个限流器对象。每个对象虽然不大,但架不住数量多,内存会直接爆炸的
而且这 10 万个 Token 里,真正活跃的有多少?可能 80% 都是注册了从来不用的"僵尸账号",每天真正在用的可能就几千个。那我为什么要为那些几个月都不来一次的 Token 常驻对象?
所以我用了 LRU 缓存做限流器对象池。
你可以理解为一个只有 5000 个车位的停车场:
- 常来的车(活跃的 Token)总有位置
- 偶尔来的车(冷门 Token)可能要重新登记一下,几个月不来的车就被踢出去了。
这样即使有 10 万个 Token,我也只需要为当前活跃的几千个保留对象。
func (m *TokenLimiterManager) getOrCreate(
sharded *ShardedLRU,
key limiterCacheKey,
rateF float64,
burst int,
) *LimiterWrapper {
if val, ok := sharded.Get(key); ok {
return val.limiter // 活跃走缓存命中
}
// 冷用户重新创建
lw := newLimiterWrapper(rateF, burst)
sharded.Add(key, &lruLimiter{limiter: lw})
return lw
}
但又有新问题了。如果几千个 Token 同时来请求,都要去这个 LRU 缓存里拿限流器,那缓存的锁就成了瓶颈。
举个例子5000 个人排队等着进同一个门得一个一个检查,队伍越来越长,那怎么跑的快?
所以我把大缓存拆成了 64 个小缓存
Token 通过 Hash 决定去哪个分片,每个分片独立加锁。现在变成了 5000 个人分散到 64 个门,每个门只需要处理 78 个人,自然就快了。
type TokenLimiterManager struct {
normal *ShardedLRU // 64 个分片
relax *ShardedLRU // 64 个分片
}
你可能注意到了,这里有两个池子。为什么要有两个?
因为我发现用户的请求其实分两类
- 一类是真正的写操作,比如创建任务或者转换图片这种
- 另一类是轻量级的查询,比如一言api、随机字符串、查询任务这种
如果把这两类请求混在一起限流,就会很蠢。
用户提交了一个长任务,然后开始每秒查询一次进度,结果因为查得太频繁把配额用光了,直接429。
所以我给轻量级请求单独准备了一个宽松模式的限流器,速率和桶大小都是正常模式的好几倍。
if isLightweightQuery {
// 轻量宽松的
allowed, burstLimit = limiter.TokenLimiter.AllowRelaxed(...)
} else {
// 重的用严格的
allowed, burstLimit = limiter.TokenLimiter.AllowNormal(...)
}
根据请求类型自动切换,用户完全无感。
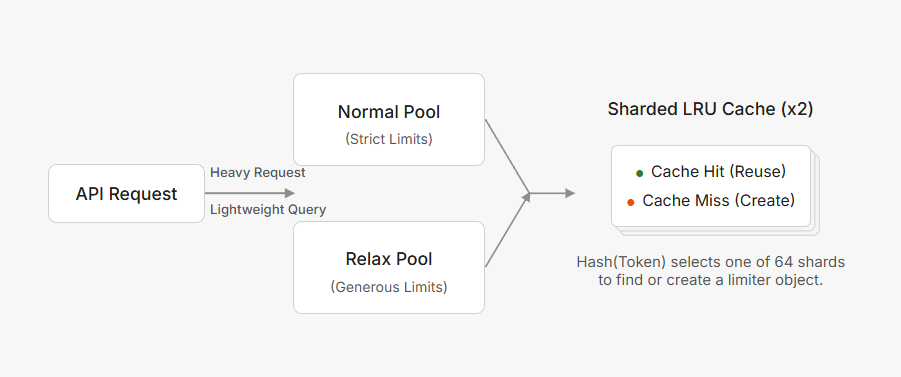
最终大概会是这样子。
2) 会Thinking的全局自适应限流
这是整个系统最核心,也是我觉得最有趣的部分。
它要解决的问题很简单:让系统始终跑在一个刚刚好的状态——
- 既不让服务器过分空闲
- 但也不要让它崩溃
如果只是和大多数项目一样设个固定的并发上限肯定是不行的。比如说我设置一个5000的并发上线对于凌晨3点系统就太空闲了,其实可以跑到 8000。
对于中午12点流量高峰,5000 根本撑不住,应该降到 3000。
所以这个上限不能是固定的,得动态调整。
那首先得让这玩意有数据源吧。
数据其实很简单:
- 系统现在是健康还是快挂了?
- 根据健康状况,该放宽还是收紧?
先说怎么感知系统健康,其实这个很简单,就是看CPU 使用率、内存使用率、请求延迟、错误率。
问题是,怎么以尽量高的性能获得这些指标?
CPU 和内存还好说,用一个独立的 goroutine 每秒从 gopsutil 读一次,然后缓存起来。这样每次做决策时直接读缓存就可以。
请求延迟也用这个办法就麻烦了。
如果我把每个请求的延迟都存下来,比如1秒有1万个请求,那就得存1万个数字。然后每秒都要把这1万个数字排序,找出第99百分位。这性能也太差了
所以我用了 t-digest 这个数据结构。
它的原理是用一组质心来近似表示整个分布,不需要存原始数据,内存占用极小(只有几百字节),但能以很高的精度估算出任意分位数。
而且多个时间窗口的 t-digest 可以快速合并,这不恰好可以用来统计吗。数据按秒分桶,分片存储,写入性能极高
有了这些指标,接下来就是决策:怎么调整并发上限?
最直接的想法是写一堆判断,假如cpu大于80巴拉巴拉巴拉..假如...:
(if-else这一块./)
if cpu > 80% {
limit = limit * 0.8 // 降20%
} else if cpu < 40% {
limit = limit * 1.2 // 升20%
}
但这有几个问题:
- 阈值怎么定最好
- 调整幅度怎么定最好
- 如果 CPU 占用老是上下抖怎么办
那有没有更好解决办法呢,那当然是有的。我用了 PID 控制器,你家空调恒温、汽车定速巡航,都是这个原理。
我们可以把调整并发上限看作一个控制问题。目标是让 P99 延迟稳定在 200ms。
PID 的三个部分干的事情是:
P(比例) 延迟离目标越远,调整越猛。比如目标 200ms,现在 400ms,差距很大,那就大幅降低并发。
I(积分) 如果延迟总是微微高于目标(比如一直在 220ms),积分项会慢慢累积,施加持续的压力,直到拉回来
D(微分) 如果延迟突然飙升(变化率大),微分项会提前刹车,防止来不及反应。
// 误差:当前延迟 vs 目标延迟
error := (latencyTarget - p99) / latencyTarget
// PID 计算调整量
u := l.pid.Compute(error, time.Now())
// 基于 PID 的相对调整
newLimit = currentLimit * (1.0 + u)
但 PID 有个问题:它是总是"事后诸葛亮"。延迟已经飙到 400ms 了,它才开始降并发,有点晚了。
所以我加了一个预测模型。它根据最近的 RPS 变化趋势,预测下一分钟的流量会涨还是会跌。
然后结合利特尔法则(并发数 ≈ 吞吐量 × 延迟),算出一个前馈的并发建议值
最后,PID 的反馈调节和预测模型的前馈建议,用几何平均融合起来:
// 前馈
feedforwardLimit := predictedRPS * latencyTarget / 1s
// PID + 前馈融合
newLimit = sqrt(pidLimit * feedforwardLimit)
这样又稳定、又有前瞻性的全局自适应限流部分就完成力。
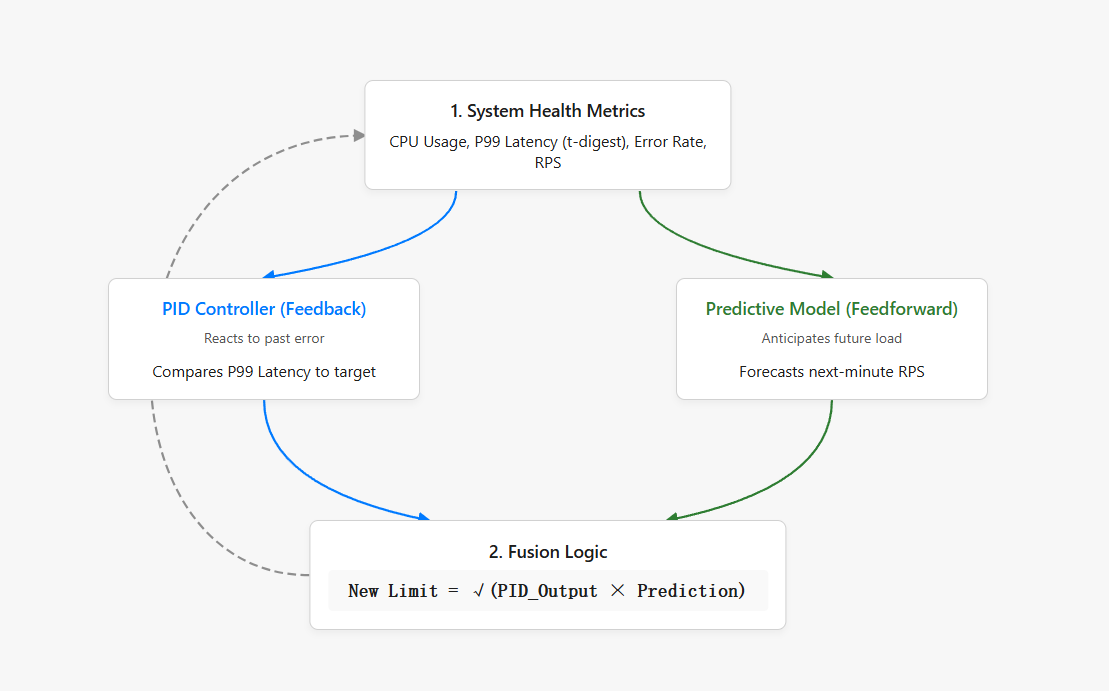
还有一些细节部分的东西:
如果 CPU 或内存过高,会额外施加一个惩罚因子,强制降并发。如果是中午高峰期,对延迟的容忍度会放宽一点;凌晨流量低的时候,对延迟要求会更严格。
还有个救命的机制,当系统过载时,会把缓存的 TTL 提高到 5 倍。比如原来缓存 1 分钟的接口,过载时会缓存 5 分钟。
这样更多请求直接从缓存返回,不用打到后端,给系统喘息的机会。等系统恢复正常了,缓存 TTL 再降回去。(至少让用户收到旧缓存比用户用不了要好)
这些都是根据实际运行情况调出来的。
3)主动防御
前面的自适应限流已经能让系统保持在健康状态了,但还有个问题:
如果真的嘿壳在恶意攻击怎么办?比如某个 IP 突然开始疯狂刷接口,或者整个系统因为下游微服务挂了导致错误率飙升
这时候光靠调整并发上限还不够,得有主动出击的能力。
先说第一个:实时 IP 频率检测。
这个原理很简单,就是来一个加一个,到阈值就把你拦了。
但问题是,在高并发下怎么做到既快又准?
如果用一个全局 map 存每个 IP 的计数,那这个 map 的锁就成了瓶颈。几万个请求同时进来,都要去抢这把锁,性能直接崩了。
所以我用了一个完全无锁的设计,每个 IP 通过 Hash 路由到一个固定的槽位,每个槽位里有 4 个计数桶,分别对应当前秒和过去 3 秒。IP 进来了,原子性地给对应桶加一,然后读取这 4 个桶的总和,判断是否超过阈值。
这个操作快到什么程度?几乎没有开销。一个请求进来,Hash 一下,定位到槽位,原子加一,读取 4 个数字求和,判断。整个过程可能就几ns。
但光拦截高频 IP 还不够,因为阈值是固定的。比如设置 100 req/s,那如果有 100 个 IP 每个刷 99 req/s 呢?每个都没超阈值,但加起来把系统打爆了。
还记得前面提到系统会用 t-digest 收集请求延迟数据吗?
其实在收集这些数据的同时,还会顺便记录每秒有哪些 IP 访问了、访问了多少次。
所以借助这个,当系统过载时,限流器就会启动这个逻辑:
- 找出过去一分钟内请求最多的那些 IP,然后根据当前系统的过载程度,动态计算一个临时的限流策略。
- 比如 CPU 越高,阈值就越低;延迟越高,允许的速率就越慢。
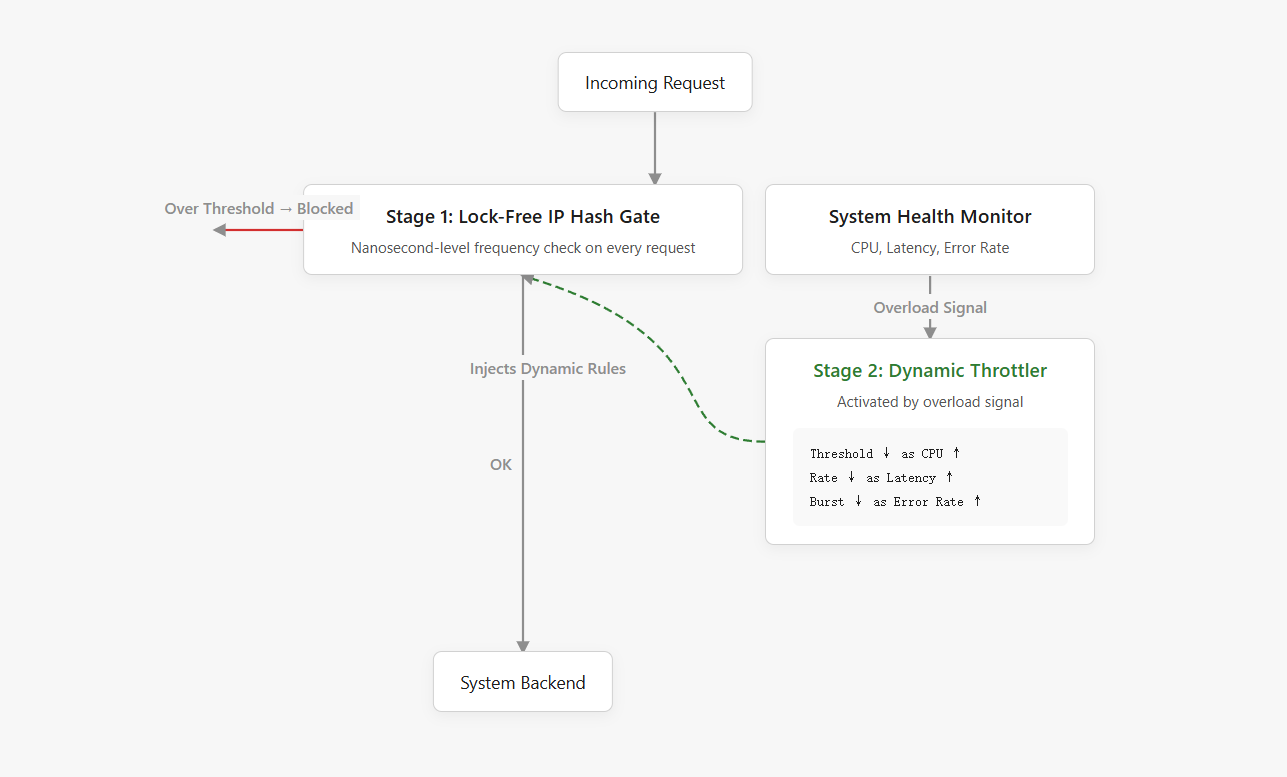
然后为这些"嫌疑 IP"创建临时的限流器,扔进缓存里,持续几分钟。
这样既不会一刀切把所有流量都拦掉,又能精准打击那些占用资源最多的 IP,给系统喘息的机会。
最后是熔断器。
这是最后的保险。
如果系统已经崩到延迟几秒、错误率 50% 了,说明可能出了严重故障(比如数据库挂了、下游服务全崩了)。这时候继续接受请求只会让情况更糟,雪崩效应会把所有东西都拖垮。
熔断器的逻辑很简单:
如果 P99 延迟和错误率同时长时间超标,直接打开,在一段时间内(比如 30 秒)拒绝绝大多数请求,只放行少量"探针"请求去试探系统是否恢复。
如果探针请求成功了,指标恢复正常了,熔断器会进入"半开"状态,逐步放行更多流量。如果持续正常,就完全关闭,恢复正常服务。如果探针又失败了,就继续保持熔断
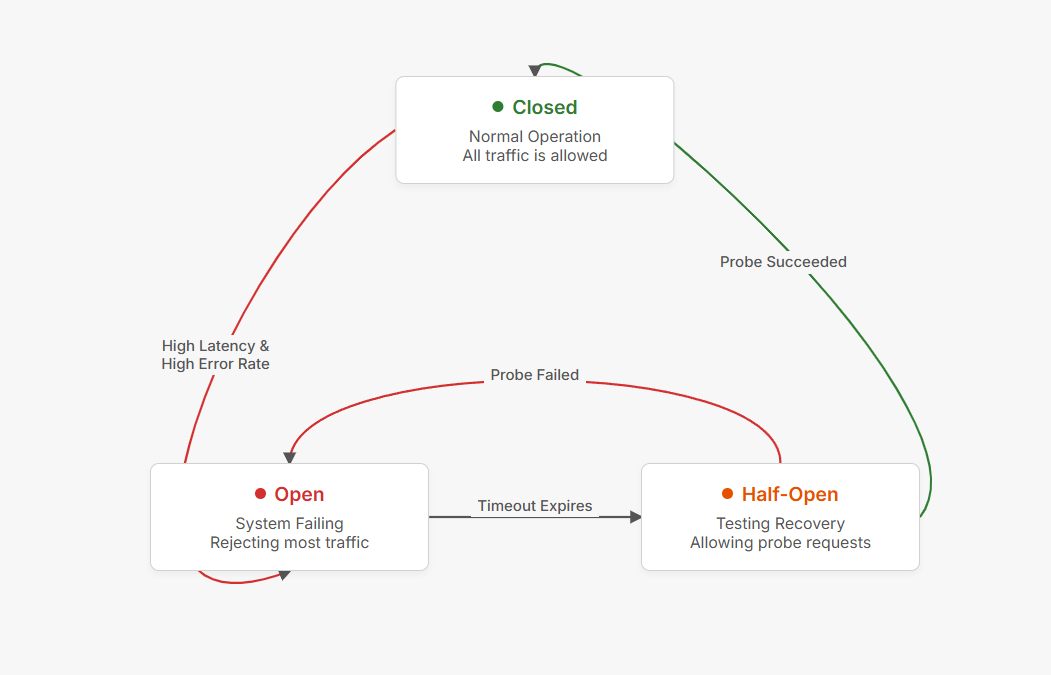
这三个机制加起来,就是第三层的主动防御了。
至此三层全部完成。
完结撒花
人类有思考能力,能根据环境变化做决策。
最近这几年,LLM 也开始有了某种思考的能力)
那限流器呢?
传统的限流器是什么样的?固定阈值、if-else 判断、死板的规则。流量来了,超过阈值就拦,低于阈值就放。
完全不管系统现在是什么状态,也不管这个流量是正常用户还是攻击者。
但我想要的不是这样。我想要的是一个会思考的限流器。
它有感官——通过 t-digest、Sysmon 这些机制知道CPU 高不高?延迟大不大?错误率如何?
它有大脑——PID 控制器 + 预测模型,根据当前状态和历史趋势,以极快的速度做出决策。该放宽还是收紧?该调整多少?
它有记忆——记住哪些 IP 在过去一分钟内访问得最频繁,在系统过载时能精准打击
它甚至有直觉——当系统崩溃时,熔断器会果断切断流量,保护自己,就像人遇到危险会本能地躲开
做着玩意的时候,我常常会陷入对意义的思考,有什么意义呢。
把这个限流器从无到有地构建出来,看到它能根据系统状态智能地调整自己,看到它在流量高峰时稳稳地撑住,看到它精准地拦截异常 IP——这种亲手创造一个会思考的系统)或许就是这件事最大的意义吧。
希望这篇文章能对你有所启发。
Ciallo~
生产环境的数据
这是 UapiPro 最近 48 小时的真实日志数据的整理:
| 指标 | 数据 |
|---|---|
| 统计周期 | 48 小时 |
| 总请求数 | 86,908 |
| 被拦截请求 | 5,097 (5.9%) |
| P50 延迟 | ~30 微秒 |
| 系统崩溃次数 | 0 |
| 人工干预次数 | 0 |
在这两天里,限流器拦截了超过 5000 次恶意请求。其中有一次攻击特别有意思,某个 IP 对 Bilibili 视频信息接口发起了疯狂的请求,单日就被拦截了 5000 多次。
这个 IP 在不到一秒内连续发了十几个请求,每次都在几十微秒内被拦截。
| 对比 | 被拦截请求 | 正常处理请求 | 性能提升 |
|---|---|---|---|
| 响应时间 | 30-80 微秒 | 100-170 毫秒 | 2000-4000 倍 |
| CPU 消耗 | 几乎为零 | 正常业务逻辑 | - |
| 后端压力 | 未到达 | 正常处理 | - |
更有意思的是,同一个 IP 的请求,有的被拦、有的放行。这说明限流器不是简单粗暴地"封 IP",而是基于实时频率做判断。当请求太快时立刻返回 429,当频率降下来时又会正常放行。这种精准的控制完全是自动的,不需要任何人工干预。
从整体性能来看:
| 请求类型 | 延迟范围 |
|---|---|
| 缓存命中 (HIT) | 15-100 微秒 |
| 缓存未命中 (MISS) | 100-200 毫秒 |
被限流器拦截的请求占总流量的 5.9%,P50 延迟稳定在 30 微秒左右。期间没有任何崩溃、没有过载、也没有人工介入调整任何参数。