我负责 uapis.cn 的大部分前端工作。uapis.cn有一个站内的文档搜索
原来我们用的是一套初版上线的现成搜索方案。
但在手机端上,它的表现非常的差,打字卡顿,出结果也慢;PC 端其实也没好到哪去,只要稍微搜长一点的词,就能明显感觉到 UI 有停滞感。
虽说视频不是很明显,但实际上可以感觉到输入就像被卡了一下。
而且那种传统的输入框 + 下拉列表的设计也不太符合现代规范,为此我还专门把它换成了全屏的命令面板(Command Palette,就是按 Ctrl+K 唤出的那种)。
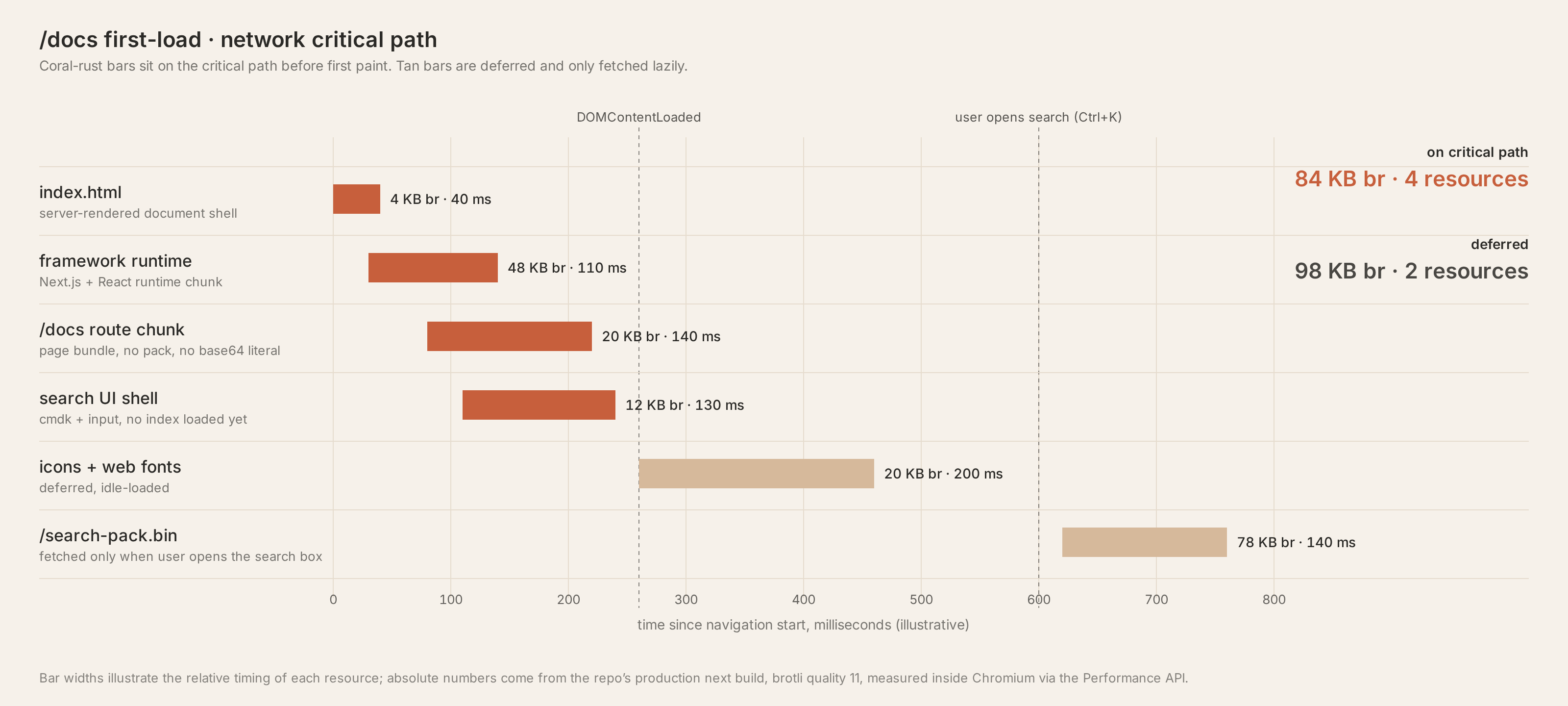
前端的 UI 骨架换完了,但如果底层的搜索引擎还是那么慢,体验上就非常脱节了。所以这两天,我把底层的搜索彻底重写了一次
依旧先看结果:
- 左边是旧的版本:依赖现 Fuse.js,首屏 JS 负担重,且查询延迟高(p50 约 13ms)。
- 中间那个是尝试的第二个版本
- 右边是现在的最新版本:自研了纯二进制的倒排索引,采用变长编码将体积极致压缩后,从首屏加载中剥离,改为异步按需获取。

这个搜索刚上线的时候,搜索做法非常暴力和简单:Next 构建阶段把所有页面的 title、URL、keywords 和部分正文抽出来,给 Fuse.js 预编译成一个json索引,然后把元数据放到前端的js代码里
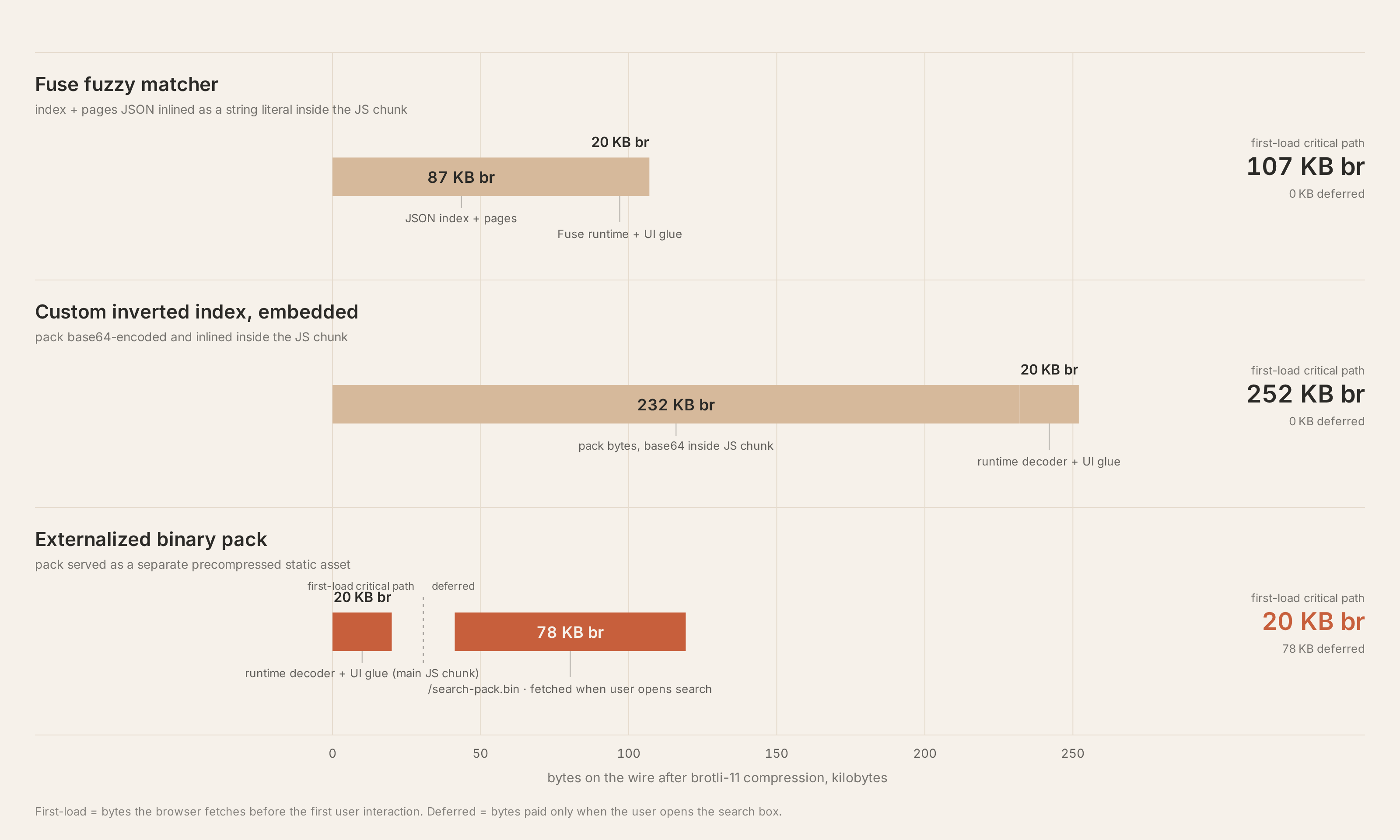
刚开始这样做是因为不需要服务端,这块搜索相关的 JSON 经过 Brotli 压缩后大约 87 KB,整个页面首屏分到搜索头上的 JS 差不多 420 KB 量级。所以大小不算离谱
可他相当的慢
QUERY LATENCY (ms) — Fuse.js
mean = 13.86
p50 = 13.32
p95 = 23.94
你可以看到,它的p50跑到13毫秒,加上防抖和主线程调度的开销,相当于用户每按一个键,这个下拉框就会非常明显的卡顿一下
而且结果也不算好,因为Fuse本质上是个模糊字符串匹配器,它算的是输入字符和目标字符有多像。对纯英文可能还好,但在中英文混杂的语料里简直是灾难。
举个例子:
- 搜
图片。 - 我们站里图片相关的 API 有十几个比如说(
image-compress、图片水印、ocr等),但Fuse算出来的相似度,会让那些标题里碰巧带了个图字的无关页页面排在前面 - 真正相关的反而被挤出了前 15 名,这导致想搜不的搜不到,不想搜的倒是很轻松的搜到了
既然Fuse不太适合我们,那就自己做一个搜索内核:
针对中文,我采用了 Bigram 切分来保证召回率。对于英文,则进行标准化的小写和词干处理。并且我同时索引了无空格的紧凑词形(例如 qqapi),这可以让引擎能够自然地应对用户因拼写习惯而省略空格的查询,极大地增强了容错性
在相关性评分上,我设计了一套多维度的动态加权模型。首先,系统会为同一个词元建立多种特征索引,如精确匹配、前缀匹配等。
在运行时,引擎会根据关键词命中的区域(例如标题的权重远高于摘要)来赋予不同的基础分。然后,再结合文档命中了多少个用户查询词进行综合打分。
最后是拼写纠错体验,索引中的所有词元预先生成了编辑距离为 1 的近邻词集合。当用户的查询无法精确命中时,它会无感地回退到这个近邻词库进行二次搜索,从而处理各种各样的拼写错误。
QUERY LATENCY (ms) — 自建倒排
p50 = 0.076
p99 = 0.605
它相比 Fuse,p50 直接降了 175 倍
下面这张图是 Node 端纯引擎延迟的对比:
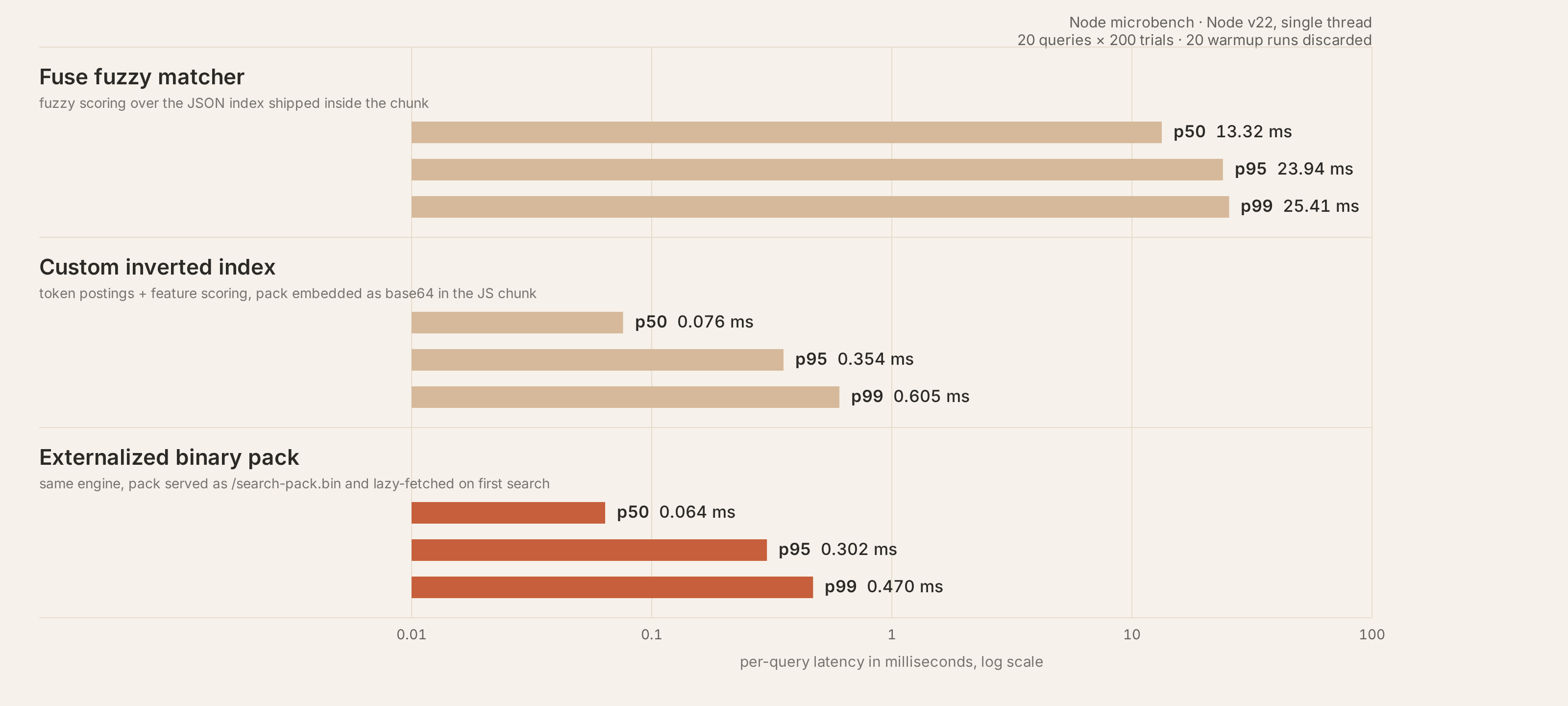
主要看第二个,最后那个是我最后的成果)
召回质量也很不错,搜图片出来的全是真正相关的 API。然后我就把它接上线(然后抓了首页的HAR),然后我意识到 Bundle 大小出了大事。
自建索引的产物是纯二进制流,raw 大小 552 KB。为了塞进前端的 JS 模块里,构建脚本直接把它做 Base64 编码,成了一个长字符串。
这就带来了灾难性的问题:Base64 本身会让体积膨胀 33%,并且Base64这种均匀分布的字符彻底破坏了数据的规律,导致 Brotli 的字典压缩几乎失效
结果就是原本 552 KB 的二进制如果直接压 Brotli 只要 116 KB,但转成 Base64 后压 Brotli,浏览器实际下载量飙到了 252 KB。
主要看第二个,最后那个是我最后的成果)
要降体积,还得往底层挖。我写了个脚本去分析那个 552 KB 的二进制包到底把空间花在哪了:
- 实际上,每个 Token 存了
e:、p:这种类型前缀,光这就吃了几十 KB。 - 而且倒排列表里的 doc id 全用定长的
u32存,其实我们的页面总数根本也用不完一个 byte
于是我上了 Varint 和 Delta 来重写二进制格式:
- 把类型前缀用 3 个 bit 打包,和 Token 长度一起塞进第一个 Byte 的高低位里。
- 倒排列表里的 ID 因为是递增的,所以只存相邻 ID 的差值,这样绝大部分数字用 1 个 byte 就能存下。
- 把原本用来做随机访问的庞大 Offset Array 删掉,改成了 Length-prefixed 顺序读取。
编码层重写完,Pack 本体大小大幅缩减:Raw 掉到了 302 KB,Brotli 压完就只有 78 KB 了。大大大大成功

但仔细想想,用户如果不按 Ctrl+K 打开搜索,这部分数据毫无意义。所以可以再省!
- 在build时生成纯二进制的
search-pack.bin和预压缩的 `search-pack.bin.br - 在运行时页面只保留极少的初始化 hook。当用户第一次唤出全屏命令面板时,才触发 fetch,解析完存在内存里。后续打开直接命中,刷新页面则命中浏览器 HTTP 缓存
二进制格式稍有 off-by-one 的位移错误,就会导致搜不到东西,而且页面还不会报错。
为了保证安全,我在替换这个版本之前写了个脚本 跑了20个基准 Query,把旧引擎和新引擎的结果集做 Jaccard 相似度对比,并且内部的 doc id 序列必须 bit-for-bit 一致
下面是脚本的结果,每个点对齐说明两个引擎返回的结果完全一致:
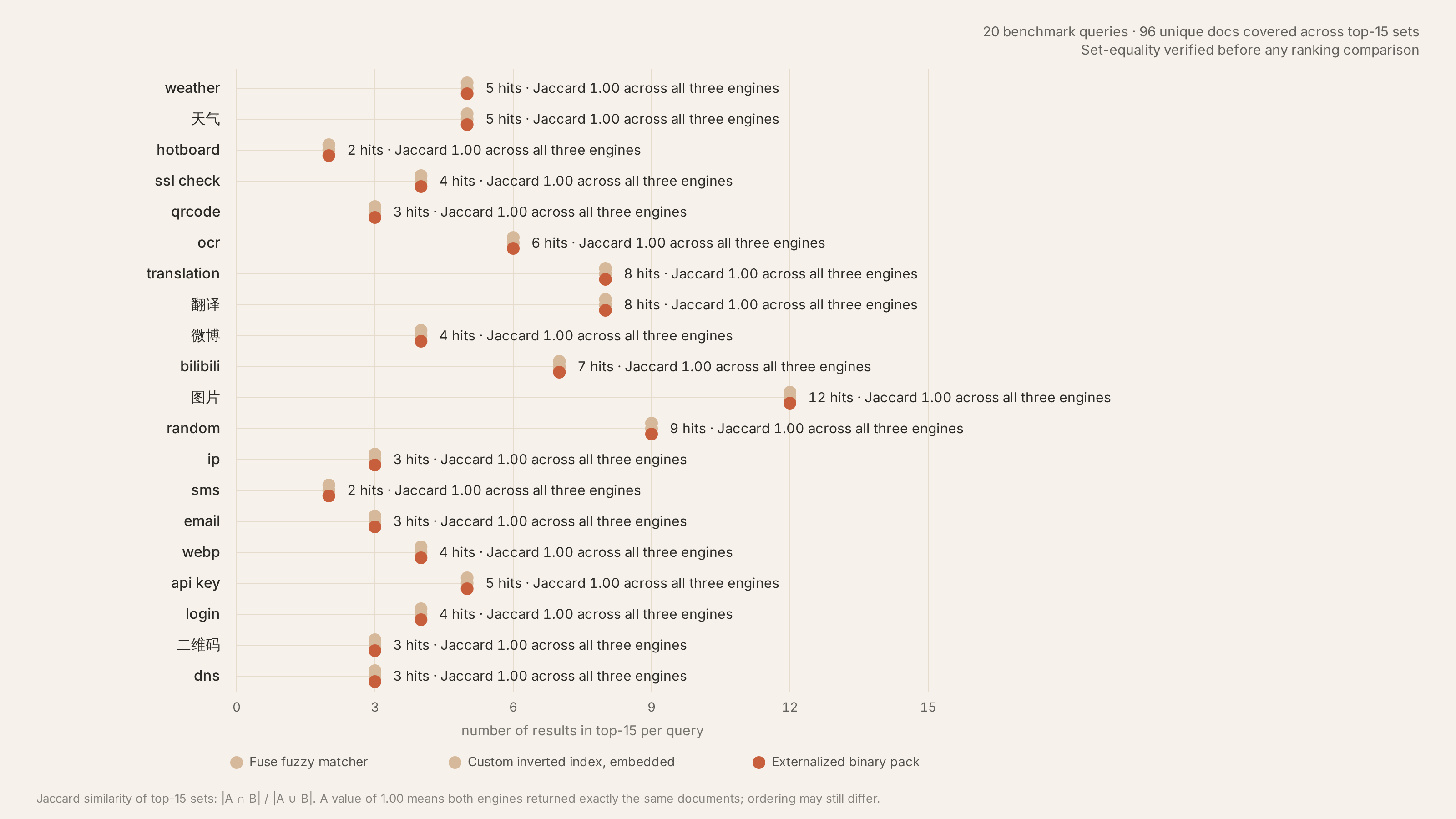
最终数据
全部干完后看一下前后的对比表:
| 以前 (Fuse.js) | 现在 | 变化 | |
|---|---|---|---|
| uapis.cn 首屏 JS 总量 (Brotli) | ~420 KB | ~110 KB | -74% |
| 搜索引擎核心资产 (Brotli) | 87 KB | 76 KB | -13% |
| 查询 p50 | 13.32 ms | 0.065 ms | -200× |
| 查询 p99 | 25.41 ms | 0.470 ms | -54× |
| 索引冷加载 | 0.67 ms | 8.1 ms | +7 ms (只一次) |
虽然说现在用户第一次打开搜索框,需要走网络去拉那个 78 KB 的包,再加上解析,冷启动会比原来慢个大概 50 毫秒。
但这样首屏js可以掉300kb左右,还是很值得的
优化用户体验依然是一个任重道远的事情,许多小细节都可能会给用户带来更好的感受。做产品一定要自己去体会,站在用户视角优化问题,相信一定可以给用户带来更好的体验。